RAG with Granite 3: Build a retrieval agent using LlamaIndex


|
Build a powerful retrieval agent using Granite 3 and LlamaIndex. Learn how to integrate advanced search and retrieval techniques to enhance information discovery in your AI-powered applications.
At a Glance
Create a retrieval augmented generation (RAG) application by using LlamaIndex and large language models (LLMs) to enhance information retrieval and generation. By integrating data retrieval with Granite LLM-powered content generation, you’ll enable intuitive querying and information retrieval from diverse document sources such as PDF, HTML, and txt files. This approach simplifies complex document interactions, making it easier to build powerful, context-aware applications that deliver accurate and relevant information.
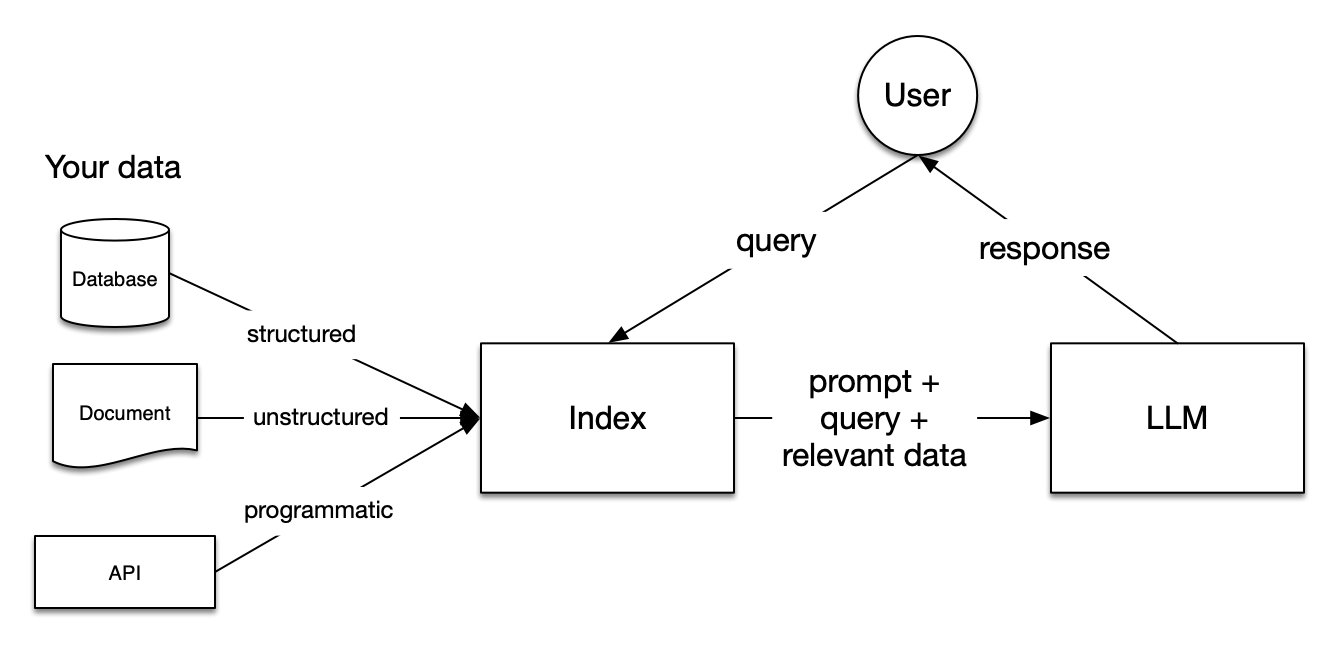
RAG framework (source: LlamaIndex)
A look at the project ahead
- Construct a RAG application: Use LlamaIndex to build a RAG application that efficiently retrieves information from various document sources.
- Load, index, and retrieve data: Master the techniques of loading, indexing, and retrieving data to ensure that your application accesses the most relevant information.
- Enhance querying techniques: Integrate LlamaIndex into your applications to improve querying techniques, ensuring that the responses are precise, contextually aware, and aligned with the most current data available.
What you’ll need
User Reviews
Be the first to review “RAG with Granite 3: Build a retrieval agent using LlamaIndex”

Related Products

Machine Learning Engineer with Microsoft Azure
Acquire the skills needed to build and deploy machine learning models using Microsoft Azure's tools and services.

How to Use ChatGPT Fluency
Learn how to effectively utilize ChatGPT for various applications, enhancing communication and productivity.

Unsupervised Learning
Understand unsupervised learning techniques for discovering patterns and insights from unlabeled data.
Building Generative Adversarial Networks
Learn to design and implement GANs for generating realistic data samples in various applications.

AI For Business Leaders
Explore the impact of AI on business strategy and decision-making for leaders in various industries.

Computer Vision
Study techniques and applications in computer vision for processing and interpreting visual data.
There are no reviews yet.